APIs, time-series, and weather Data
Results
ggplot() +
geom_sf(data = net_migration, aes(fill = groups, color = groups), lwd = 0.1) +
geom_sf(data = tidycensus::state_laea, fill = NA, color = "black", lwd = 0.1) +
scale_fill_brewer(palette = "PuOr", direction = -1) +
scale_color_brewer(palette = "PuOr", direction = -1, guide = "none") +
coord_sf() +
labs(title = "Net migration per 1000 residents by county",
subtitle = "US Census Bureau 2017 Population Estimates",
fill = "Rate",
caption = "Data acquired with the R tidycensus package")## old-style crs object detected; please recreate object with a recent sf::st_crs()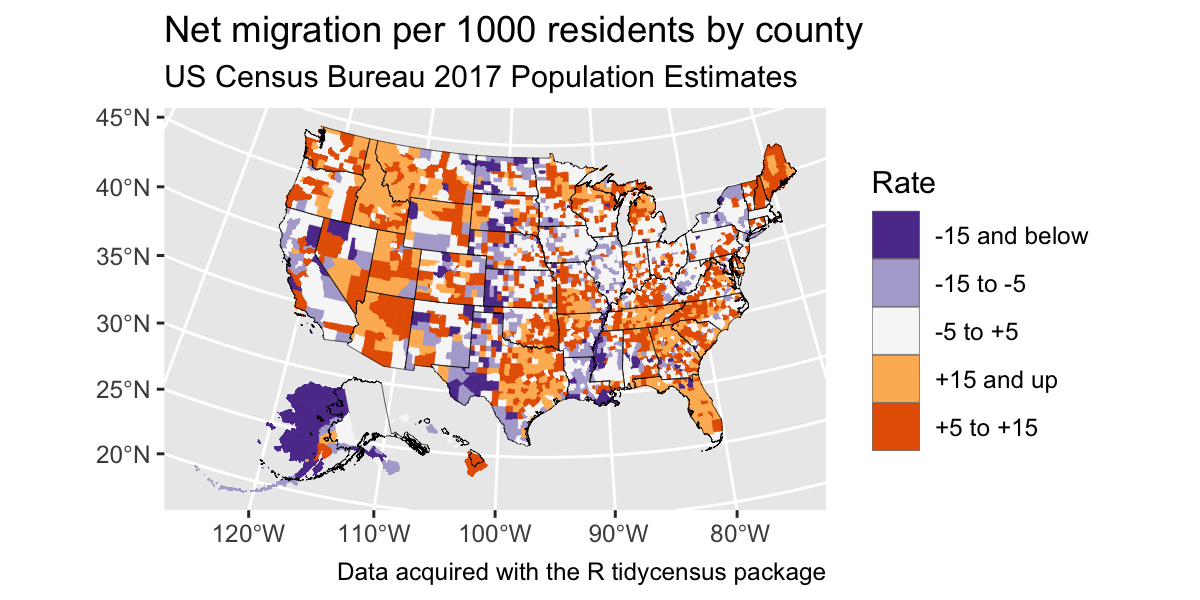
Results
library(rasterVis)
gplot(NED)+
geom_raster(aes(fill=value))+
scale_fill_viridis_c()+
geom_sf(data=UB,inherit.aes = F,fill="transparent",col="red")+
geom_sf(data=st_centroid(UB),inherit.aes = F,fill="transparent",col="red")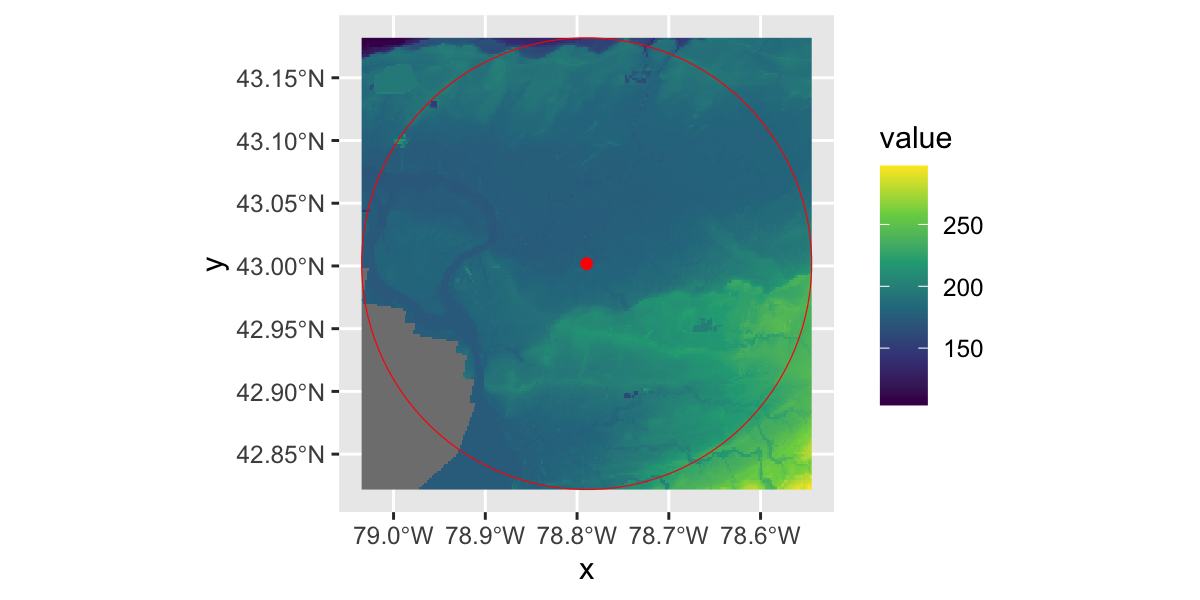
gplot(DAYMET$tmax[[1:10]])+
geom_raster(aes(fill=value))+
facet_wrap(~variable)+
scale_fill_viridis_c()+
geom_sf(data=st_transform(UB,crs(DAYMET$tmax)),inherit.aes = F,fill="transparent",col="red")+
labs(title="Daymet Maximum Temperature")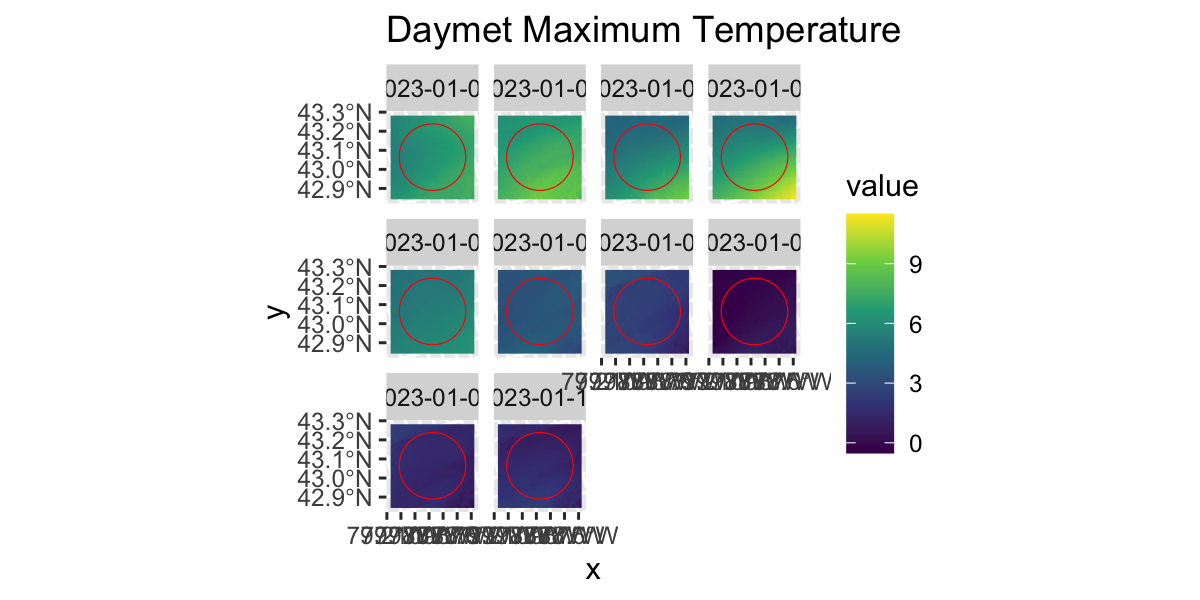
Plot temperatures
ggplot(daily,
aes(y=tmax,x=date))+
geom_line(col="red")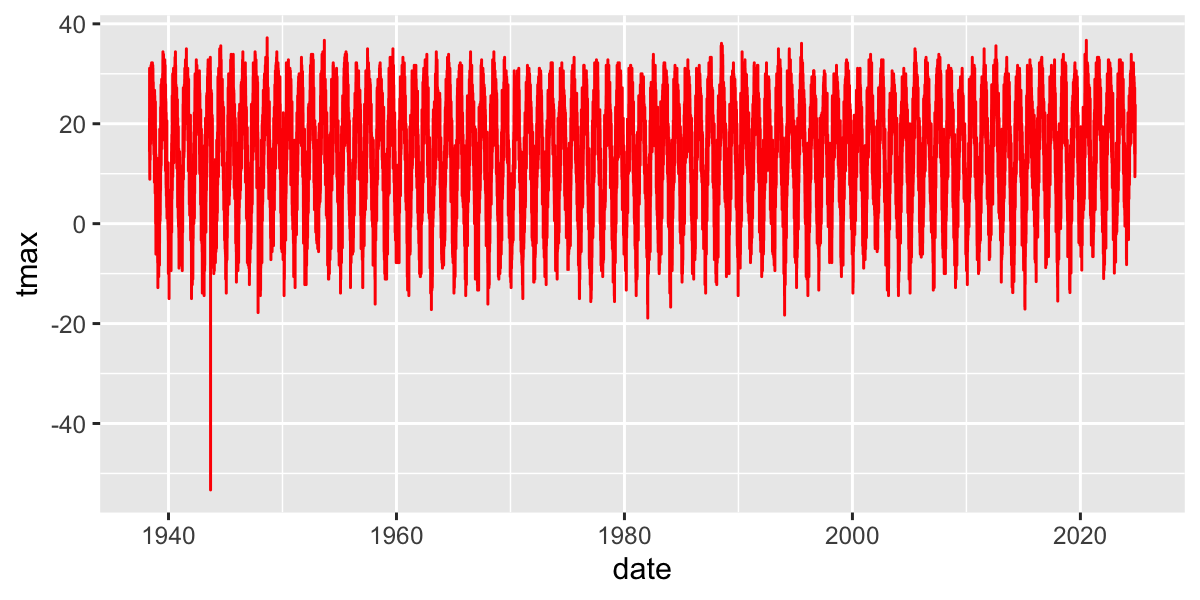
Limit to a few years
daily_recent=filter(daily,date>as.Date("2020-01-01"))
ggplot(daily_recent,
aes(y=tmax,x=date))+
geom_line(col="red")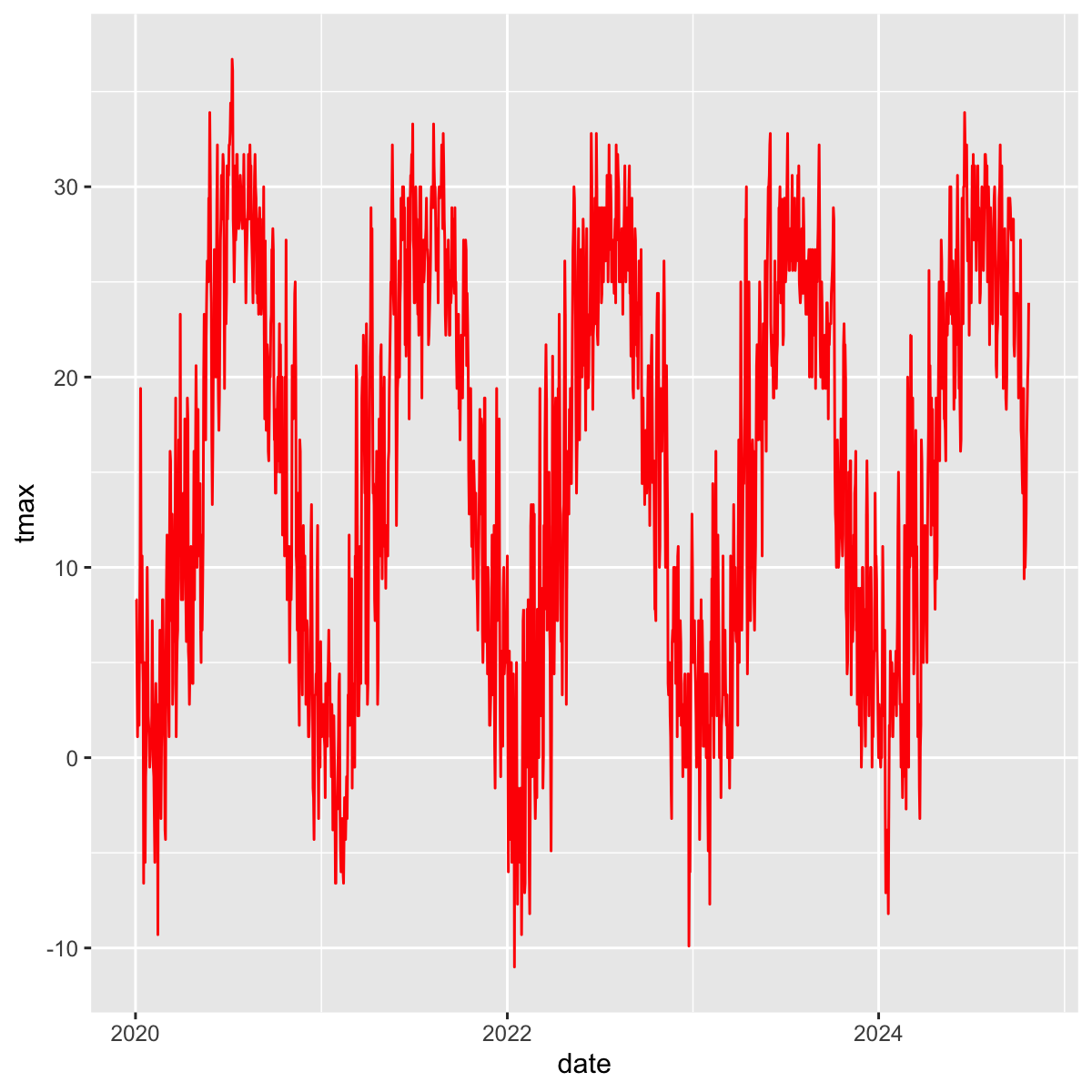
d_rollmean%>%
ggplot(aes(y=tmax,x=date))+
geom_line(col="grey")+
geom_line(aes(y=tmax.60),col="red")+
geom_line(aes(y=tmax.b60),col="darkred")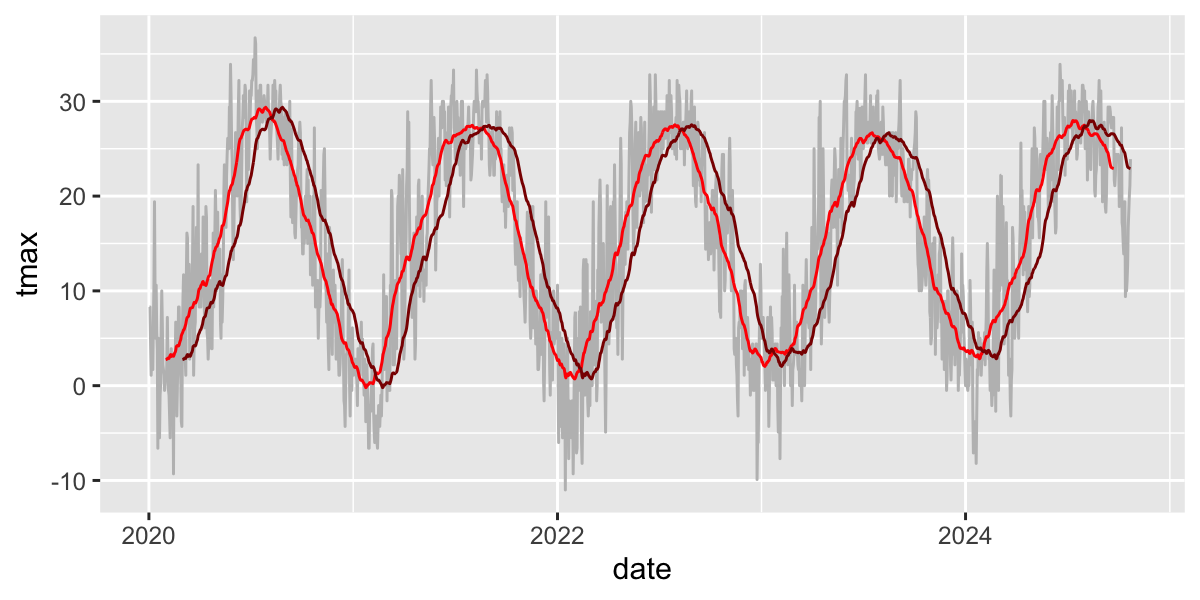
Temporal autocorrelation
Values are highly correlated!
ggplot(daily_recent,aes(y=tmax,x=lag(tmax)))+
geom_point()+
geom_abline(intercept=0, slope=1)## Warning: Removed 10 rows containing missing values or values outside the scale range
## (`geom_point()`).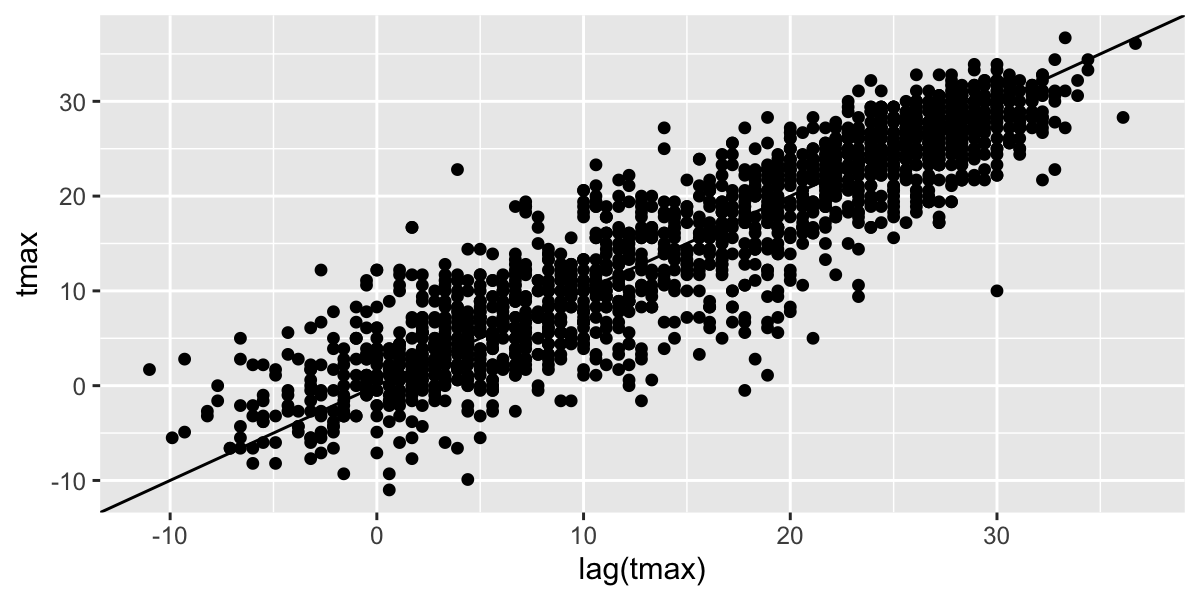
Autocorrelation
acf(tmax.ts,lag.max = 365*3,na.action = na.exclude )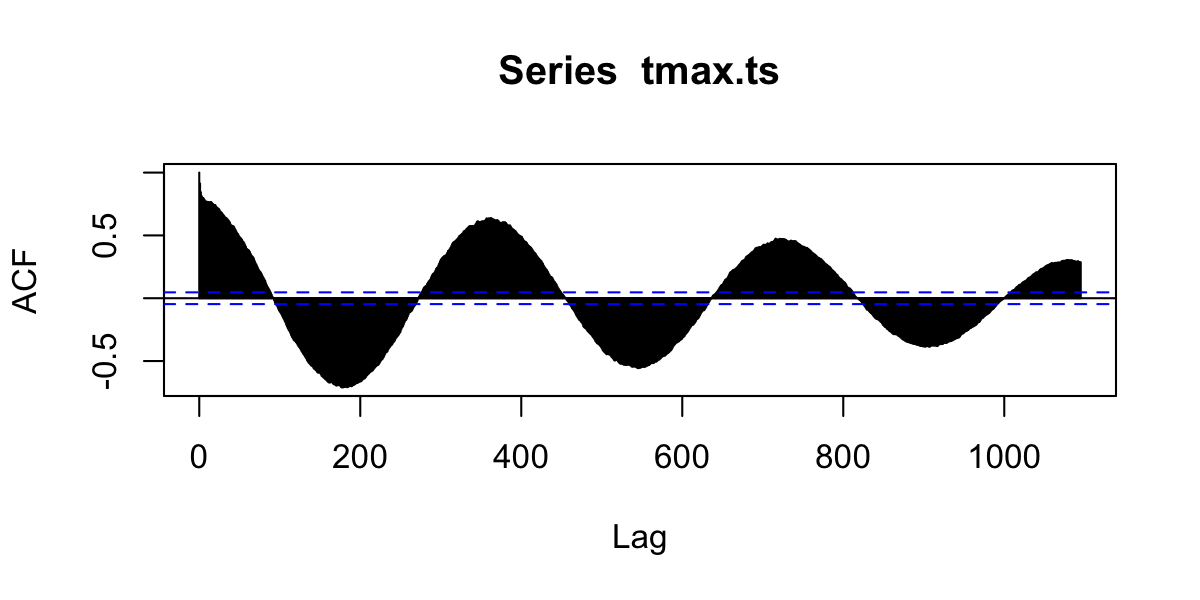
Partial Autocorrelation
pacf(tmax.ts,lag.max = 365,na.action = na.exclude )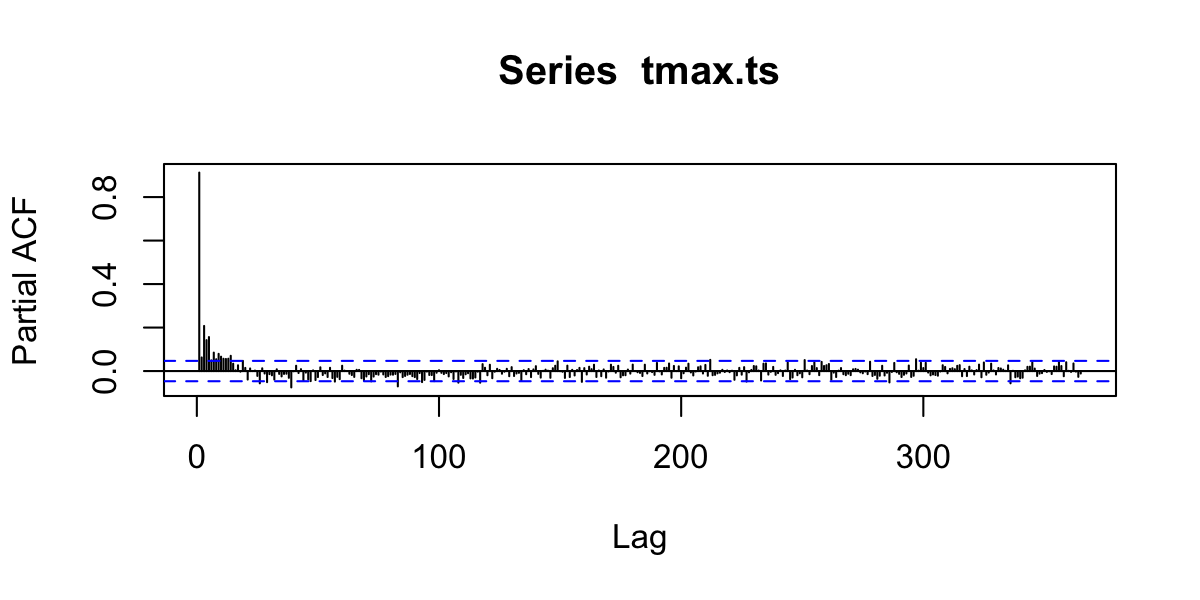
But be careful, there were missing data in the beginning of the record
daily2%>%
group_by(year)%>%
summarize(n=n())%>%
ggplot(aes(x=year,y=n))+
geom_line()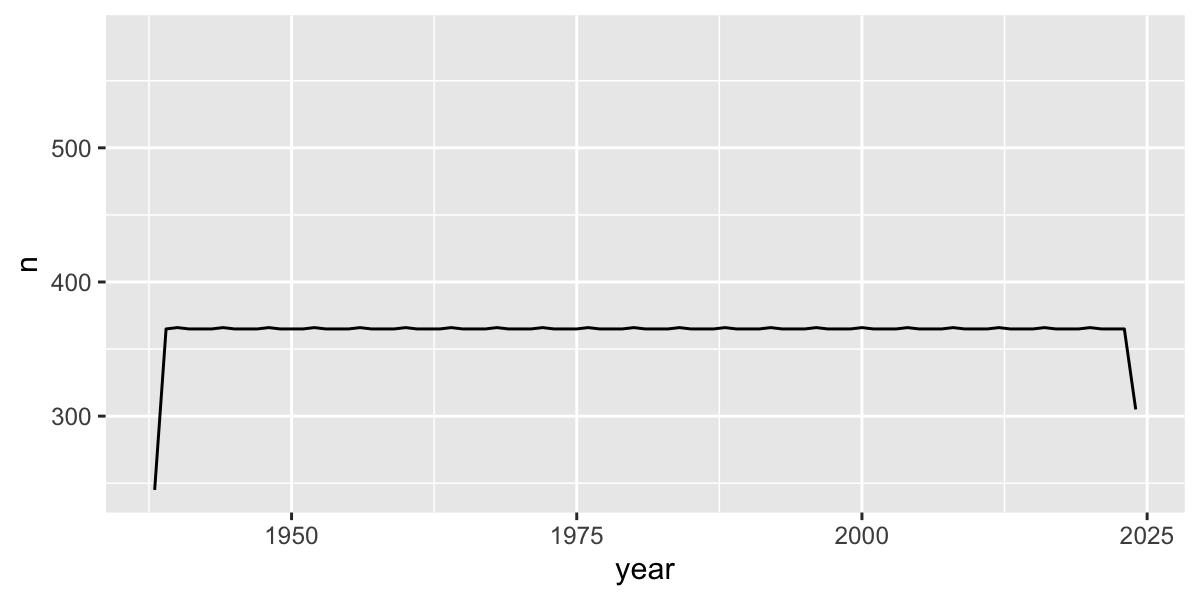
Plot 10-year means (excluding years without complete data):
daily2%>%
filter(year>1938, year<2024)%>%
group_by(dec)%>%
summarize(
n=n(),
tmax=mean(tmax,na.rm=T)
)%>%
ggplot(aes(x=dec,y=tmax))+
geom_line(col="grey")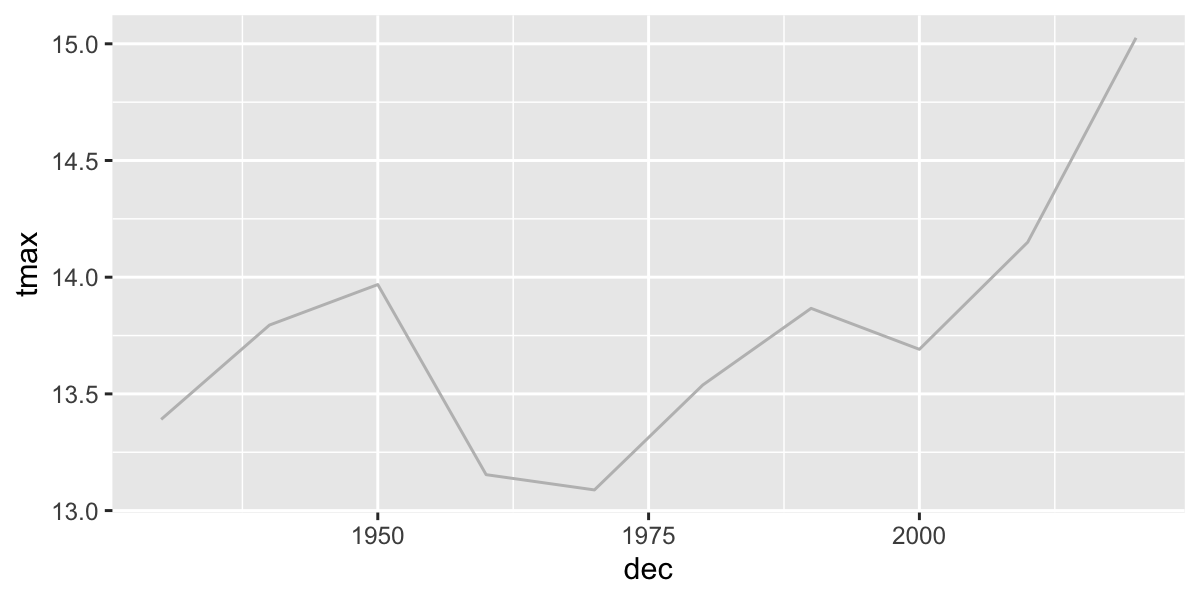
Then plot all years (in grey) and add 2024 in red.
ggplot(df,aes(x=doydate,y=tmax,group=year))+
geom_line(col="grey",alpha=.5)+ # plot each year in grey
stat_smooth(aes(group=1),col="black")+ # Add a smooth GAM to estimate the long-term mean
geom_line(data=filter(df,year==2024),col="red")+ # add 2023 in red
scale_x_date(labels = date_format("%b"),date_breaks = "2 months") +
xlab("Day of year")## `geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'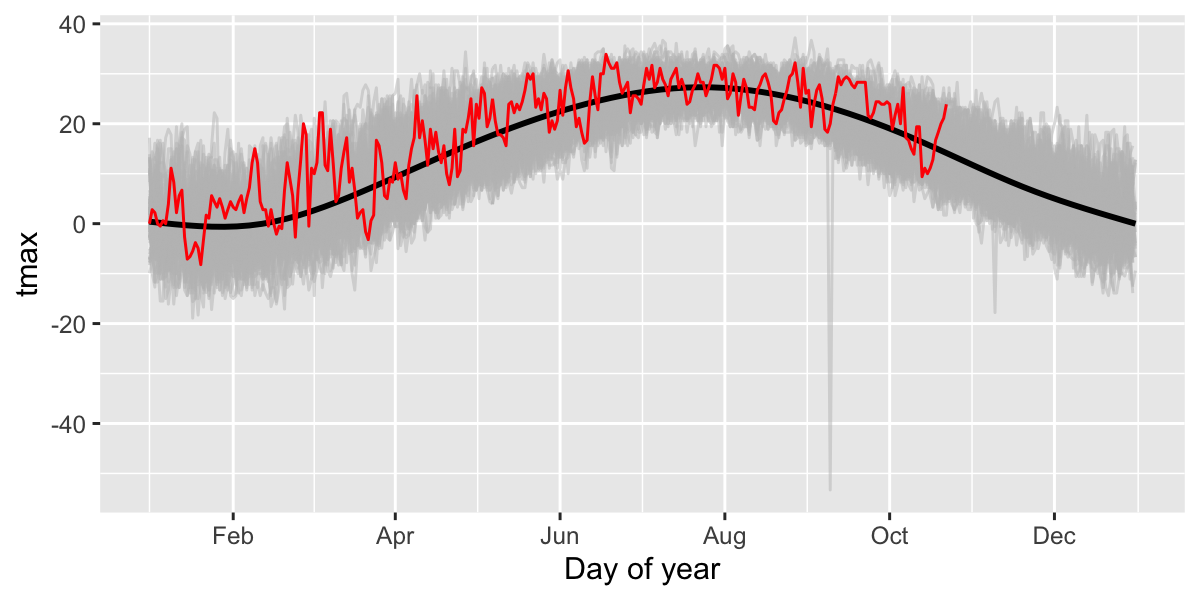
Then ‘zoom’ into just the past few months and add 2024 in red.
ggplot(df,aes(x=doydate,y=tmax,group=year))+
geom_line(col="grey",alpha=.5)+
stat_smooth(aes(group=1),col="black")+
geom_line(data=filter(df,year==2024),col="red")+
scale_x_date(labels = date_format("%b"),date_breaks = "2 months",
lim=c(as.Date("2024-08-01"),as.Date("2024-10-31")))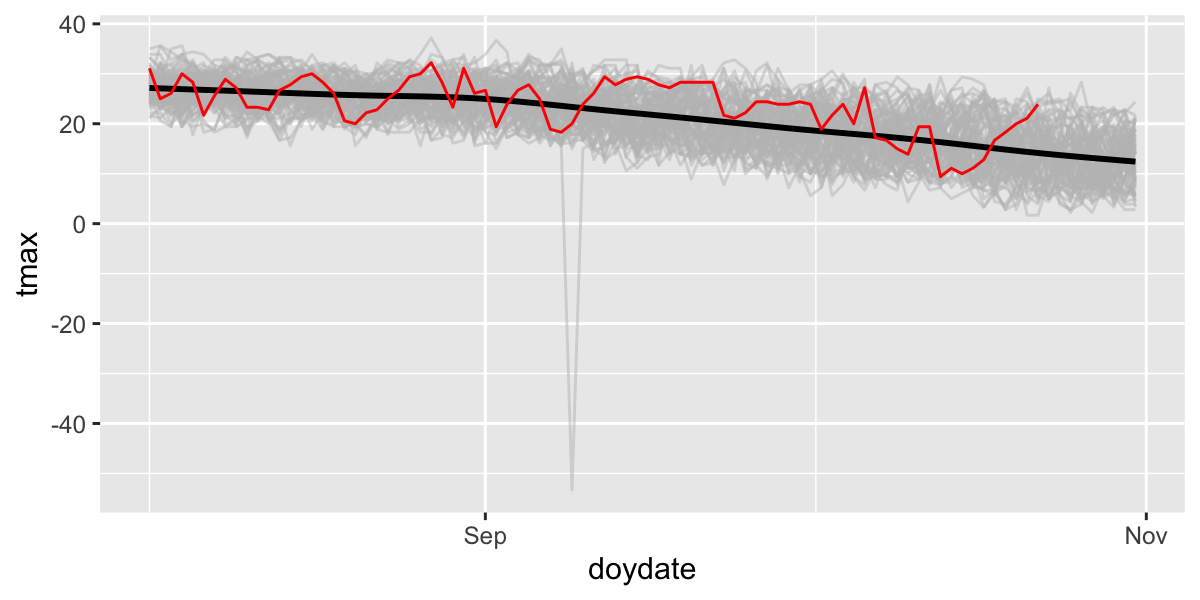
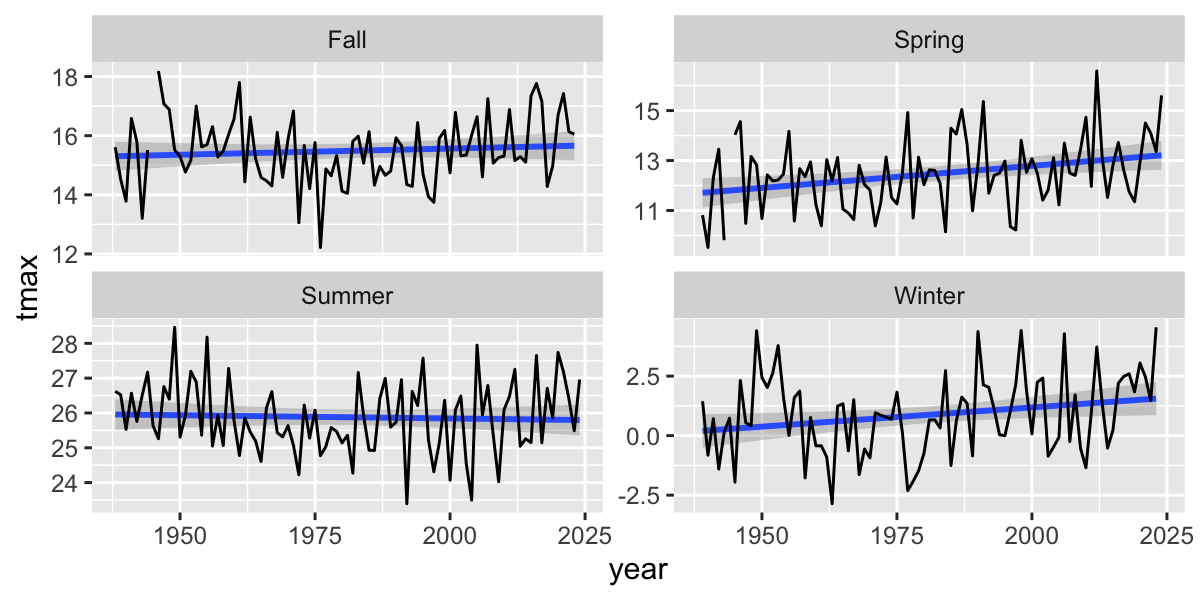
Seasonal Trends
seasonal |>
filter(!is.na(season)) |>
ggplot(aes(y=tmax,x=year))+
facet_wrap(~season,scales = "free_y")+
stat_smooth(method="lm", se=T)+
geom_line()## `geom_smooth()` using formula = 'y ~ x'