Tracking Hurricanes!
Analyze historical storm data from NOAA
Reading
- Overview of the International Best Track Archive for Climate Stewardship (IBTrACS)
- Performing Spatial Joins with sf
Tasks
- Write a .Rmd script to perform the following tasks
- Intersect the storms with US states to quantify how many storms in the database have hit each state.
Libraries & Data
library(sf)
library(tidyverse)
library(ggmap)
library(spData)
data(world)
data(us_states)Objective
In this case study you will download storm track data from NOAA, make
a summary plot, and quantify how many storms have hit each of the United
States. This will require you to use a spatial join
(st_join).
Your goal
# Download a csv from noaa with storm track information
dataurl="https://www.ncei.noaa.gov/data/international-best-track-archive-for-climate-stewardship-ibtracs/v04r01/access/csv/ibtracs.NA.list.v04r01.csv"
storm_data <- read_csv(dataurl)## Rows: 127009 Columns: 174
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (149): SID, SEASON, BASIN, SUBBASIN, NAME, NATURE, LAT, LON, WMO_WIND, ...
## dbl (12): NUMBER, USA_SSHS, TOKYO_GRADE, TOKYO_LAND, CMA_CAT, NEWDELHI_CI,...
## lgl (12): TOKYO_R50_DIR, TOKYO_R30_DIR, HKO_CAT, KMA_CAT, KMA_R50_DIR, KMA...
## dttm (1): ISO_TIME
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Your desired figure looks something like the following:
| state | storms |
|---|---|
| Florida | 89 |
| North Carolina | 67 |
| Georgia | 61 |
| Texas | 56 |
| Louisiana | 53 |
Steps
- Use the code above to download the storm data and create an object
called
storm_data - Wrangle the data
- Create a new column with just the year using
year(ISO_TIME)(yearis in the lubridate package) - Filter to storms 1950-present with
filter() - Use
mutate_if()to convert-999.0toNAin all numeric columns with the following command from thedplyrpackage:mutate_if(is.numeric,function(x) ifelse(x==-999.0,NA,x)) - Use the following command to add a column for decade:
mutate(decade=(floor(year/10)*10)) - Convert the data to a sf object with
st_as_sf(coords=c("LON","LAT"),crs=4326) - Use
st_bbox()to identify the bounding box of the storm data and save this as an object calledregion.
- Create a new column with just the year using
- Make the first plot
- Use
ggplot()to plot theworldpolygon layer and add the following: - add
facet_wrap(~decade)to create a panel for each decade - add
stat_bin2d(data=storms,aes(y=st_coordinates(storms)[,2],x=st_coordinates(storms)[,1]),bins=100) - use
scale_fill_distiller(palette="YlOrRd",trans="log",direction=-1,breaks = c(1,10,100,1000))to set the color ramp - use
coord_sf(ylim=region[c(2,4)],xlim=region[c(1,3)])to crop the plot to the region.
- Calculate table of the five states with most storms.
- use
st_transformto reprojectus_statesto the reference system of thestormsobject (you can extract a CRS from a sf object withst_crs(storms) - Rename the
NAMEcolumn in the state data tostateto avoid confusion with storm name usingselect(state=NAME) - Perform a spatial join between the storm database and the states
object with:
storm_states <- st_join(storms, states,join = st_intersects,left = F). This will ‘add’ the state to any storm that was recorded within that state. - Use
group_by(state)to group the next step by US state - use
summarize(storms=length(unique(NAME)))to count how many unique storms occurred in each state. - use
arrange(desc(storms))to sort by the number of storms in each state - use
slice(1:5)to keep only the top 5 states ```
- use
Try to replicate the following graphic using the data you transformed above.
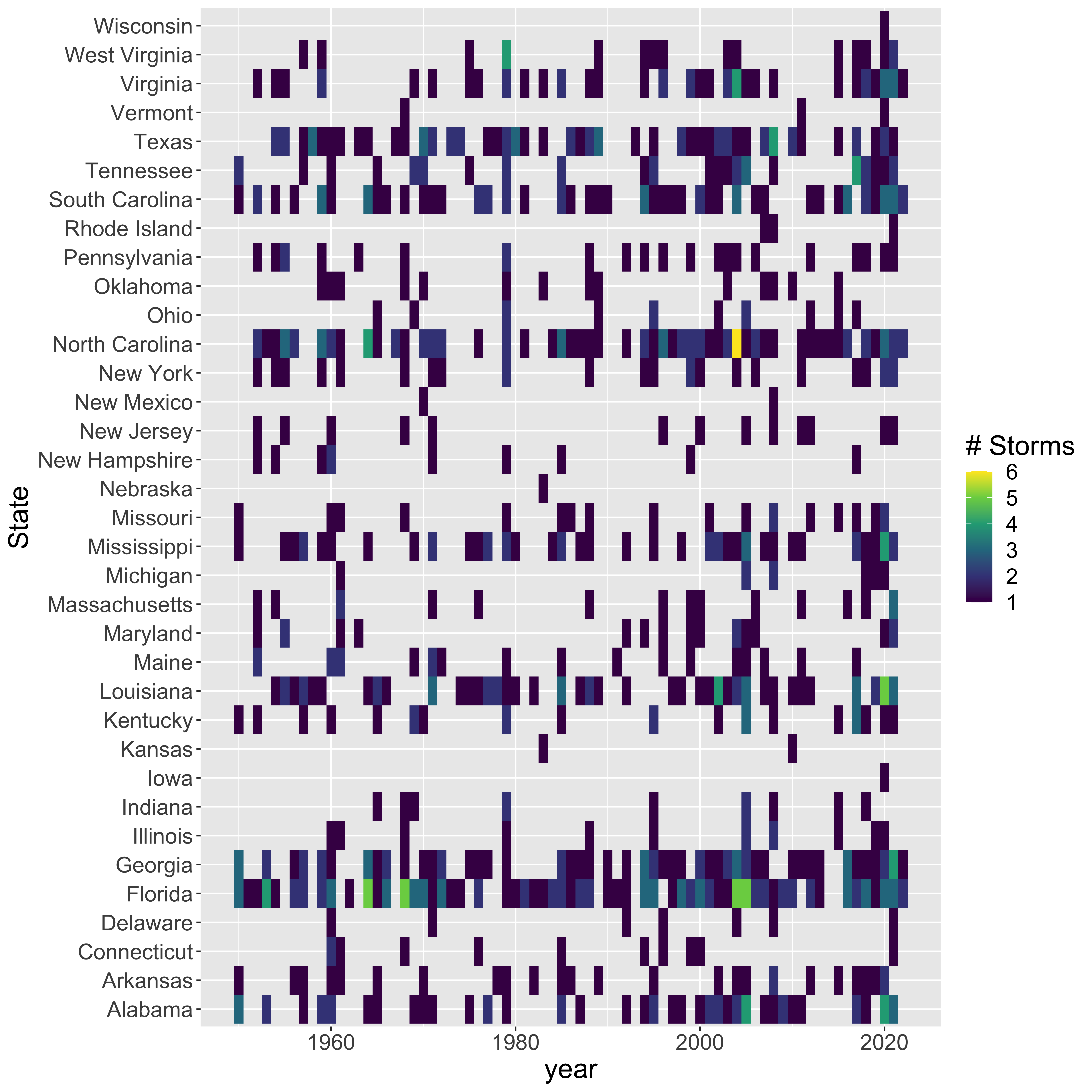
Can you sort the rows (states) in order of storm frequency (instead of alphabetical)?